Xpath Nedir?
Xpath, belirli bir XML dosyasının içerisinde aradığınız bilgilere tamamıyla ulaşmanızı sağlayan bir XML kılavuzudur. Xpath ile birlilkte XML gibi karmaşık yapılı ve karmaşık bir dilli dosyaların içerisinde kolaylıkla dolaşabilmekteyiz. Tabi burada sadece XML değil, HTML gibi farklı birçok veride de bizlere bilgi sunabilmektedir. Şimdi de Xpath aracını kullanırken kullanılan popüler ve temel Xpath komutları konusuna geçiş yapmak istiyorum. Bu sayede Xpath’i daha yakından tanımış olacağız.Xpath Temel Komutları
1 – Başlık Etiketleri
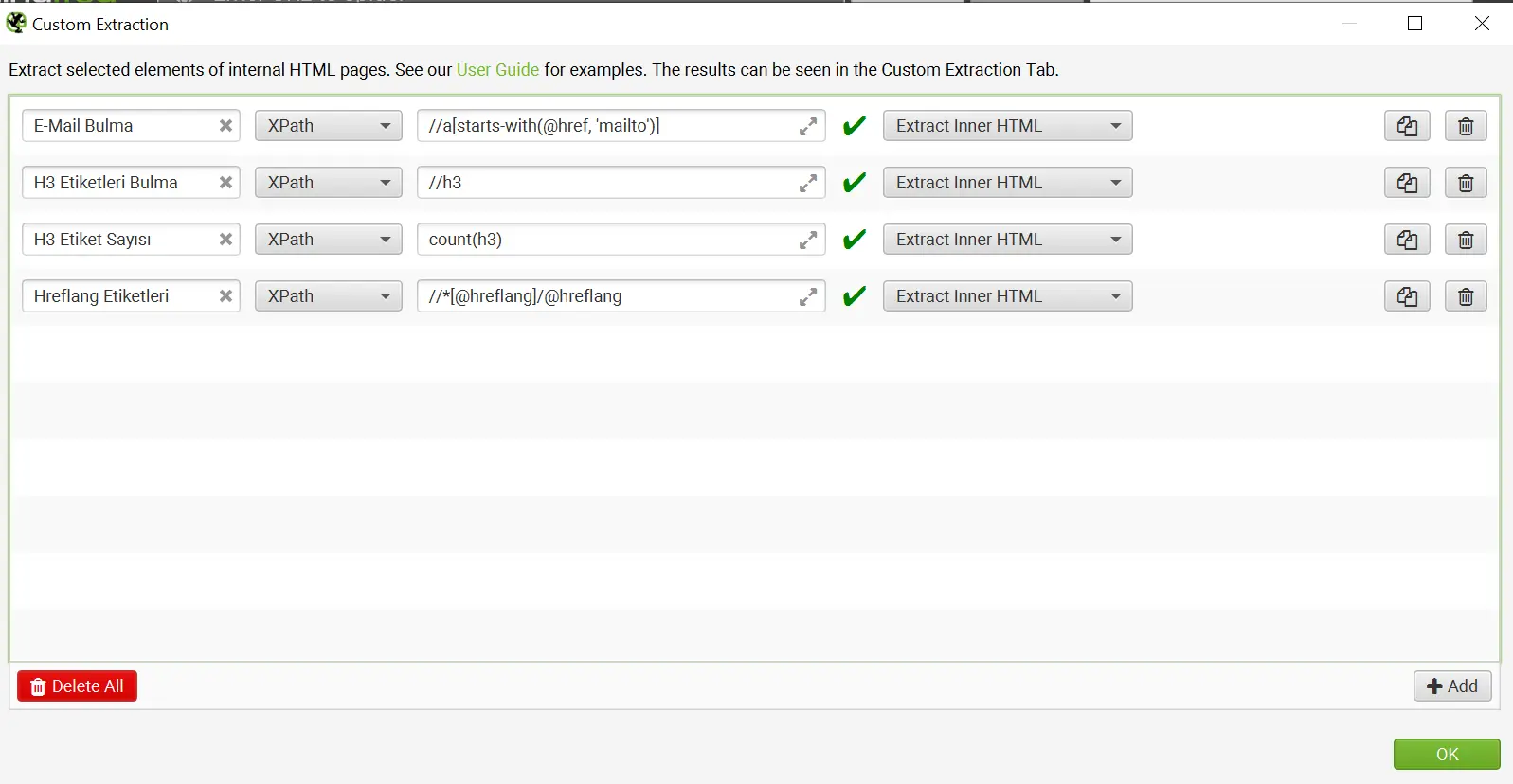
Crawl yaparken genel olarak SEO analiz aracı bizlere h1 ve h2 başlıkları hakkında bilgi vermektedirler. Bu noktada “//hx” komutu ile birlikte sayfada yer alan diğer başlık etiketlerini de kolaylıkla görebilmekteyiz. > Sayfada yer alan h3 etiketini bulabilmek için //h3 komutu yeterli olacaktır. > Sayfa içerisinde yer alan h3 etiketlerinin sayısı için count(h3) komutu yeterli olacaktır. >Sayfada yer alan ilk 10 h3 etiketini bulabilmek için /descendant::h3[position() >= 0 and position() <= 10] komutu yeterli olmaktadır. > Sayfada yer alan h3’lerin uzunluk hesaplaması için de string-lenght(//h3) komutu bulunmaktadır.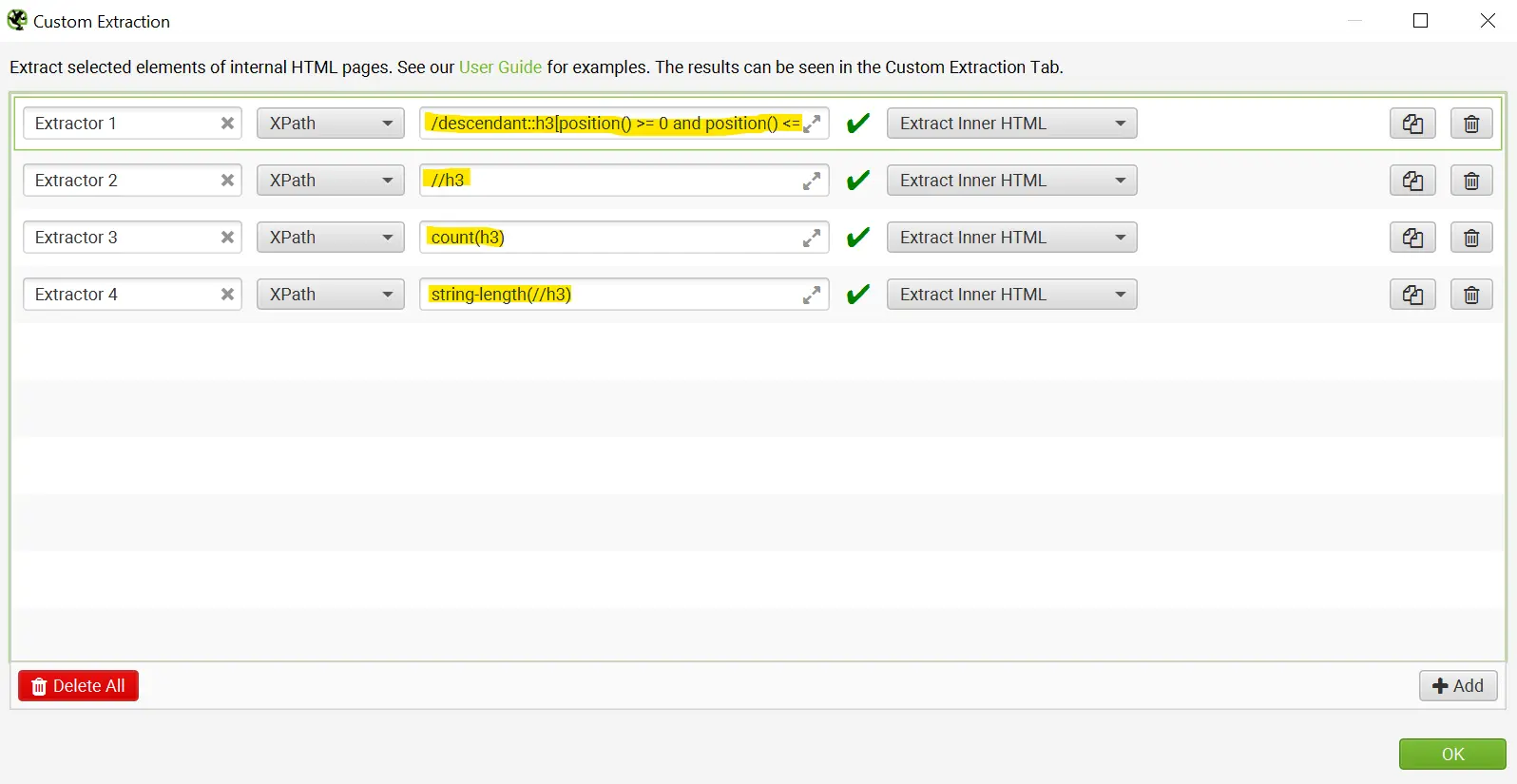
2 – Hreflang Etiketleri
Arama yapacağınız sayfada hreflang etiketlerini bulmak çok daha basit bir durumda. Hreflang için “//*[@hreflang]/@hreflang” etiketi yeterli olacaktır.
3 – Yapılandırılmış Verileri Bulma
Günümüzde yapılandırılmış veriler sıklıkla kullanılmaktadır. Özellikle de e-ticaret gibi satış platformlarında sıklıkla kullanılmaktadır. Peki yapılandırılmış verileri nasıl bulacağız? Hiç endişe etmeyin çünkü bunları da kolaylıkla görebilmekteyiz. Yapısal veriler için de “//*[@itemtype]/@itemtype” komutunu kolaylıkla kullanabilirsiniz.
4 – E-Mail Adreslerini Bulma
Sayfadaki tüm E-mail adreslerini tek bir komut ile bulabilmek mümkün. E-mail adresleri için “//a[starts-with(@href,’mailto’)]” komutunu kolaylıkla kullanabilirsiniz.
5 – AMP Sayfalar
AMP ile oluşturulan ve kullanıcıya sunulan sayfaları bulabilmek için “//head/link[@rel=’amphtml’]/@href ” komutunu kullanabilirsiniz.
6 – iFrame
Sayfada yer alan iframe etiketlerini bulabilmek için “//iframe/@src” komutunu kolaylıkla kullanabilirsiniz. Sayfada yer alan YouTube videoları için de “//iframe[contains(@src ,’www.youtube.com/embed/’)]” kodunu kullanabilirsiniz.
7 – Sosyal Medya Etiketleri
Sayfa içerisinde yer aaln Twitter Card gibi sosyal medya etiketlerini de Xpath SEO ile birlikte bulabilmek mümkün. Gelin hızlıca bu kodların neler olduğuna hızlıca bir göz atalım.- //meta[starts-with(@property, ‘og:title’)]/@content
- //meta[starts-with(@property, ‘og:description’)]/@content
- //meta[starts-with(@property, ‘og:type’)]/@content
- //meta[starts-with(@property, ‘og:site_name’)]/@content
- //meta[starts-with(@property, ‘og:image’)]/@content
- //meta[starts-with(@property, ‘og:url’)]/@content
- //meta[starts-with(@property, ‘fb:page_id’)]/@content
- //meta[starts-with(@property, ‘fb:admins’)]/@content
- //meta[starts-with(@property, ‘twitter:title’)]/@content
- //meta[starts-with(@property, ‘twitter:description’)]/@content
- //meta[starts-with(@property, ‘twitter:account_id’)]/@content
- //meta[starts-with(@property, ‘twitter:card’)]/@content
- //meta[starts-with(@property, ‘twitter:image:src’)]/@content
- //meta[starts-with(@property, ‘twitter:creator’)]/@content
8 – Meta Viewport Etiketi
Meta viewport etiketlerini bulabilmek için de “//meta[@name=’viewport’]/@content” komutlarını kullanabilirsiniz.
8 – Attribute Komutu
Sayfada yer alan bazı attribute komutlarına erişebilmek mümkün. Gelin bu komutlara yakından göz atalın.- //*[@id=”örnek”] | Sayfa içerisinde yer alan id’si “örnek” olan bütün elementleri bulur.
- count(//*[@id=”örnek”]) | Sayfa içerisinde yer alan id’si “örnek” olan elementin sayısını belirtir.
- //*[@class=”örnek”] | Sayfa içerisinde yer alan class’ı “örnek” olan tüm elementler bulunur.
- count(//*[@class=”örnek”]) | Sayfa içerisinde yer alan class’ı “örnek” olan element sayısını verir.
9 – Count Kullanımı
Yazmış olduğunuz tüm Xpath’in başına “count” eklerseniz, aradığınız sonuç sayısına kolaylıkla ulaşım sağlayabilirsiniz. Örnek: “count(//h3)” | Buradaki komutta sayfada yer alan tüm H3 etiketlerinin sayısı karşımıza gelecektir.
Screaming Frog: Xpath Kullanımı
Yukarıda başlıklar halinde sırası ile temel Xpath komutları listesini hazırlayarak sizlerle paylaştım. Peki bu komutları nereye ve nasıl yazacağız? İşte bu sorunun cevabına şimdi geçiş yapacağız. İlk olarak Xpath alanını ve kullanımını göstermek istiyorum. Sonrasında da bazı ayarlarına kısaca göz atacağız. Bu sayede bir adım daha Xpath anlama noktasına yaklaşmış olacağız. 1 | Screaming Frog’u açalım. Sonrasında Configuration > Custom > Extraction alanını seçelim.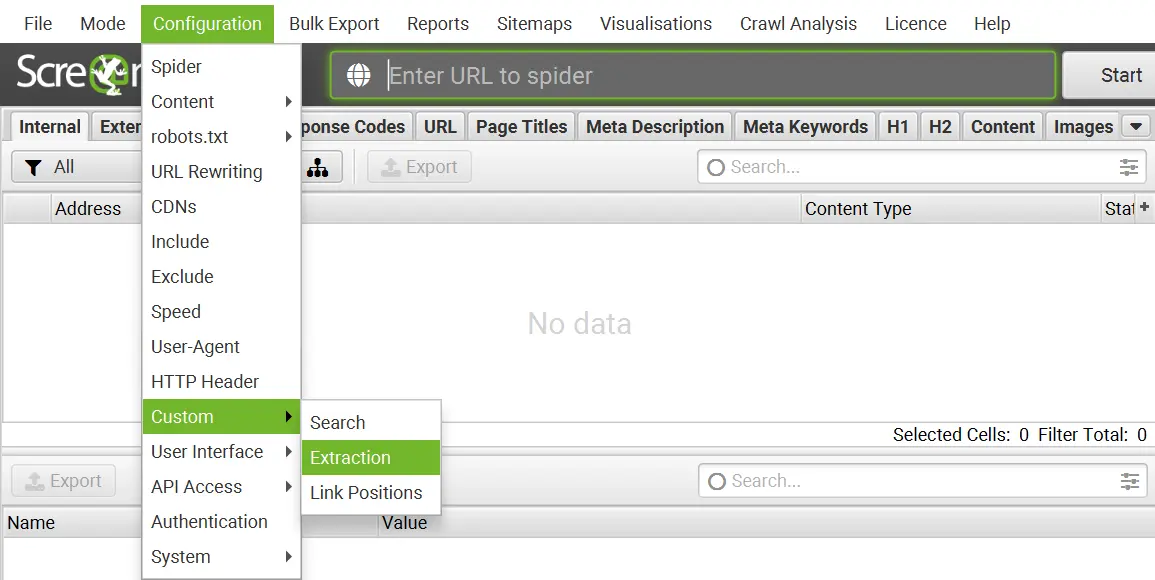
- Extractor 1: Buraya komutumuzun ismini giriyoruz.
- Enter Xpath: Buraya ise yukarıda yer alan komutlardan istediğinizi girin.
- Add: Buradan da yeni komut eklemek için istediğiniz kadar ekleme yapabilirsiniz.
 Xpath
On-Page SEO analiz yaparken detaylı bir şekilde araştırma yapmak isteyenler için, olmazsa olmaz araçlardan birisidir. Bu noktada Xpath hakkı yenmeyecek olan isimlerden birisidir. Öğrenmesi ve yazması kolay olması nedeniyle, en kısa zamanda komutları da kolaylıkla ezberleyebilirsiniz. Bu teknik ile birlikte analizleriniz çok daha detaylı ve kolay bir şekilde gerçekleşecektir.
Xpath
On-Page SEO analiz yaparken detaylı bir şekilde araştırma yapmak isteyenler için, olmazsa olmaz araçlardan birisidir. Bu noktada Xpath hakkı yenmeyecek olan isimlerden birisidir. Öğrenmesi ve yazması kolay olması nedeniyle, en kısa zamanda komutları da kolaylıkla ezberleyebilirsiniz. Bu teknik ile birlikte analizleriniz çok daha detaylı ve kolay bir şekilde gerçekleşecektir.
Extra Diğer Xpath Komutları
Sayfa içinde yer alan “XML” kelimesini içeren tüm anchor textler üzerinden hangi URL’lere link gittiğini görebilmek için > “//a[contains(.,’XML’)]/@href” komutunu kullanabilirsiniz. Sayfa içinde “XML” geçen tüm anchor textleri bulabilmek için ise > “//a[contains(.,’XML’)]” komutunu kullanabilirsiniz. İçerisinde “XML” geçen tüm linkleri bulabilmek için > “//a[contains(@href, ‘seo’)]@href” komutu yeterli olacaktır. Sayfada yer alan tüm nofollow linkleri tespit etmek için ise > “//a[@rel=”nofollow”]” komutunu ekleyebilirsiniz. Not: Xpath komutlarını eklerken büyük/küçük harf duyarlılığına dikkat etmeniz gerekmektedir. XML yazdığınız bir komutta, sayfa içerisinde xml kavramları bulunamaz. Bu sorunu çözebilmek için “//a[contains(translate(., ‘ABCDEFGHIJKLMNOPQRSTUVWXYZ’, ‘abcdefghijklmnopqrstuvwxyz’),’xml’)]/@href” komutunu kullanabilirsiniz.Konu Başlıkları


![Blog Nasıl Açılır? Blogger SEO Ayarları [2026]](https://www.zeusdijital.com/wp-content/uploads/2022/04/blog-nasil-acilir-2.jpg)
![Ticimax SEO Nedir? Ticimax SEO Nasıl Yapılır? [2026]](https://www.zeusdijital.com/wp-content/uploads/2022/06/ticimax-nedir-ticimax-seo-rehberi.webp)
